


Introduction
Data lineage, a concept that has gained significant attention in recent years, refers to the process of tracking and documenting the origin, movement, and transformation of data throughout its lifecycle. In the context of clinical research, data lineage plays a crucial role in ensuring the integrity, reliability, and reproducibility of research findings. By providing a comprehensive view of how data is collected, processed, and analyzed, data lineage enables researchers to maintain transparency, comply with regulatory requirements, and facilitate collaboration among stakeholders.
This blog post aims to explore the concept of data lineage in clinical research, highlighting its importance, challenges, and best practices for implementation. We go through the various stages of the data lifecycle, discuss the benefits of adopting good data lineage practices, and provide insights into how organizations can leverage technology to streamline their processes with regards to data intiatives.
Whether you are a researcher, data manager, or IT professional involved in clinical research, understanding the significance of data lineage is essential for driving data-driven decision-making and advancing scientific knowledge.
Understanding the difference between data lineage and Metadata in clinical research
In clinical research, both data lineage and metadata are crucial for effective data management, but they serve distinct purposes. Here’s a table with a breakdown of their differences:
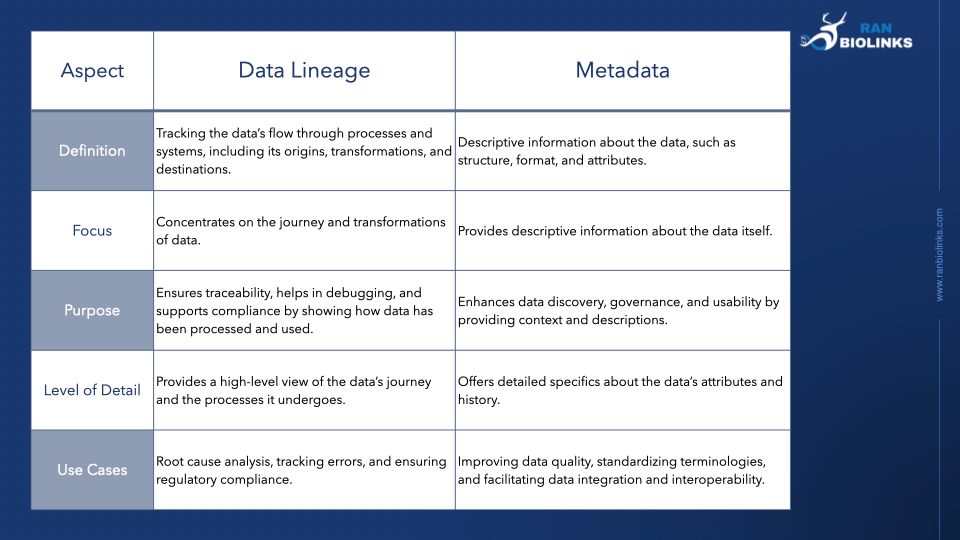
Data lineage refers to the tracking of data as it flows through various processes and systems. It provides a detailed map of the data's lifecycle, including its origins, transformations, and final destinations. This is crucial for understanding how data has been manipulated and used, which is essential for ensuring data integrity, quality, and compliance in clinical research. Key aspects of data lineage include:
- Origin Tracking: Identifying the initial source of the data.
- Transformation Documentation: Recording any changes made to the data.
- Usage Tracking: Understanding where and how the data is used.
- Audit Trails: Maintaining a chronological record of data-related activities.
Metadata, on the other hand, is data about data. It provides descriptive information about the data, such as its structure, format, and other attributes. Metadata helps in managing and organizing data, making it easier to find, understand, and use. In clinical research, metadata can include:
- Data Definitions: Descriptions of what the data represents.
- Data Quality: Information about the accuracy, completeness, and reliability of the data.
- Data Ownership: Details about who is responsible for the data.
- Data Provenance: Historical records of the data, including its origin and any changes made to it.
While data lineage and metadata are interconnected and both vital for comprehensive data management, they serve different roles. Data lineage maps out the data’s journey, while metadata offers detailed background information. Together, they help maintain data integrity, quality, and compliance in clinical research.
The Role of Data Lineage in Clinical Research
Data lineage is essential in clinical research for ensuring data integrity, facilitating reproducibility, maintaining regulatory compliance, and enabling effective data governance. By tracking data from its origin through its transformations and final use, data lineage provides a comprehensive audit trail that verifies the validity and reliability of research findings. This record is crucial for identifying and rectifying discrepancies or errors during data ingestion, processing, analysis, and reporting.
Moreover, data lineage allows researchers to reproduce results, enhancing the transparency and credibility of their work. It supports compliance with regulatory requirements such as HIPAA and GDPR by providing evidence of data handling practices and ensuring the protection of sensitive patient information. As clinical research becomes more data-driven and complex, the importance of data lineage cannot be overstated. Understanding data flows and dependencies through data lineage enables effective data governance, facilitating informed decision-making, risk assessment, and robust data management policies.
Ensuring data integrity
Data integrity is the cornerstone of clinical research, and data lineage plays a vital role in upholding this principle. By documenting the origin, transformations, and movements of data, data lineage provides an audit trail essential for identifying and rectifying discrepancies. Researchers can trace the provenance of each data point, ensuring accuracy, completeness, and consistency, thereby preventing data manipulation and mitigating erroneous conclusions.
Facilitating reproducibility
Reproducibility is a cornerstone of scientific research, and data lineage facilitates this by documenting data’s journey, including specific data sources, processing steps, and analytical methods. This transparency allows other scientists to validate results independently, ensuring the reliability and credibility of the research. Data lineage helps identify and mitigate sources of variability or bias, promoting knowledge sharing, collaboration, and scientific progress..
Maintaining compliance with regulatory standards
In clinical research, maintaining compliance with regulatory standards such as HIPAA, GDPR, and FDA guidelines is crucial. Data lineage provides an audit trail that demonstrates adherence to these requirements, capturing details such as data access controls and anonymization techniques. This record helps organizations respond to regulatory inquiries or audits promptly and provides evidence of secure and ethical data handling practices, mitigating the risk of penalties and safeguarding trust.
Enabling effective data governance
Effective data governance is essential for the quality, security, and ethical use of data in clinical research. Data lineage helps organizations establish robust data governance frameworks by providing a clear understanding of data flows and dependencies. This insight is invaluable for developing data governance policies addressing data quality, security, access, and retention. By documenting the entire data lifecycle, data lineage facilitates transparency, accountability, and collaboration, fostering responsible data stewardship in clinical research.
Key Components of Data Lineage
The key components of data lineage include data origin and source, data transformations, data validations, and data movements.
- Data origin and source refer to the initial point of data creation, such as patient records, laboratory tests, or imaging studies.
- Data transformations encompass various processes that modify the data, including data processing, cleaning, and integration. These transformations ensure that the data is accurate, consistent, and ready for analysis.
- Data validations involve quality checks and error detection and correction mechanisms to maintain the integrity and reliability of the data.
- Finally, data movements include data transfers and archiving, which ensure that the data is securely stored and can be accessed when needed.
Establishing a Data Lineage Framework
To effectively trace the journey of clinical research data, it is crucial to establish a robust data lineage framework. This framework should encompass well-defined policies and procedures that govern how data lineage is captured, maintained, and utilized throughout the research lifecycle.
Implementing specialized data lineage tools and technologies, such as data lineage software and metadata management systems, can significantly streamline the process of tracking data provenance. These tools enable automated capture and visualization of data flows, dependencies, and transformations, providing a comprehensive view of the data's journey.
Integrating data lineage practices seamlessly into the research workflow is key to ensuring consistent and reliable lineage information. This integration may involve incorporating data lineage checkpoints at critical stages of the research process, such as data collection, processing, analysis, and reporting.
Additionally, providing thorough training and education to research team members on data lineage concepts, tools, and best practices is essential for fostering a culture of data transparency and accountability. When researchers are equipped with the necessary knowledge and skills, the organizations they belong to can ensure that data lineage becomes an integral part of their clinical research ecosystem, ultimately enhancing the quality, reproducibility, and integrity of research findings.
Benefits of Effective Data Lineage
Implementing a robust data lineage system in clinical research offers numerous advantages:
- Enhanced data integrity and reliability: Data lineage allows researchers to track the origin and transformations of data, ensuring its accuracy and reliability throughout the research process. This is crucial for maintaining the integrity of clinical study results.
- Improved regulatory compliance: Data lineage provides a clear audit trail of data flows and transformations, essential for demonstrating compliance with regulatory requirements such as those set by the FDA or other regulatory bodies. This transparency is necessary for regulatory audits and ensuring adherence to legal requirements in clinical research.
- Efficient troubleshooting and error tracing: When issues arise in clinical data, data lineage enables researchers to identify and isolate problems in the data pipeline quickly. It facilitates swift resolution of issues, minimizing downtimes and enhancing operational efficiency in clinical studies.
- Better understanding and trust in data: Data lineage provides the necessary context surrounding an organization's data, showing the entire journey from source to destination, including any transformations along the way. This helps clinical researchers ensure they are using accurate, complete, and trustworthy data to drive their research decisions.
- Facilitation of impact analysis: Data lineage allows researchers to predict the effects of changes to data sources, transformations, or destinations. This represent invaluable in risk assessment and change management for clinical studies, ensuring that modifications to the data pipeline are thoroughly evaluated before implementation.
- Support for data governance: Data lineage supports effective data governance by providing a comprehensive understanding of data flows and dependencies. It enables clinical research organizations to establish data governance policies, ensuring data quality, security, and privacy throughout the research process.
- Time-saving in manual analysis: Data lineage can save significant time for IT and research teams by automating the process of tracking data flows and transformations. Researchers can then focus more on analysis and interpretation than manual data mapping.
- Enhanced reproducibility: By providing a clear picture of how data was collected, processed, and analyzed, data lineage enables other researchers to understand and potentially replicate study results, which is crucial for scientific validity in clinical research.
- Improved data quality management: Understanding data lineage allows for careful examination and validation of data quality at each stage of the research process. It helps identify and rectify any anomalies, errors, or inconsistencies, ensuring high-quality data for clinical studies.
- Support for data exploration and viability assessment: Data lineage tools can help researchers explore data assets more efficiently and assess their viability for specific research purposes.
Challenges and Considerations
Implementing data lineage in clinical research presents several challenges and considerations that organizations must address to ensure effective tracking and management of data flows. Here are some of the key challenges
- Complex Data Systems: Modern data ecosystems have intricate interconnected components that make tracking data paths difficult. The complexity increases with the number of systems and processes involved in data handling.
- Lack of Standardized Tools: Universal tools and methodologies for documenting data's life cycle are absent. This can lead to inconsistencies and gaps in lineage information, complicating the implementation process.
- High Data Volume and Velocity: The sheer volume and speed at which data is generated and processed necessitate efficient tracking mechanisms. Managing large datasets in real-time can be resource-intensive and challenging.
- Diverse Data Sources and Transformation Methods: The variety of data sources and the different methods used to transform data add layers of complexity to mapping data lineage. Each source and transformation might require unique approaches to track and document the data's journey accurately.
- Scalability: As organizations grow, the data they handle also increases. A scalable data lineage system is essential to accommodate this growth without performance degradation. The system must be fault-tolerant to recover from failures without losing critical lineage information.
- Evolving Data Regulations: Changing data protection laws, such as GDPR and CCPA, have significant implications for data lineage. Organizations must ensure that their lineage practices are adaptable to remain compliant with these regulations, requiring ongoing adjustments to tracking mechanisms and documentation processes.
- The granularity of Data Tracking: Determining the appropriate level of detail (granularity) for effective lineage tracking is challenging. Too much granularity can lead to information overload, while too little can miss important details. Finding the right balance is critical.
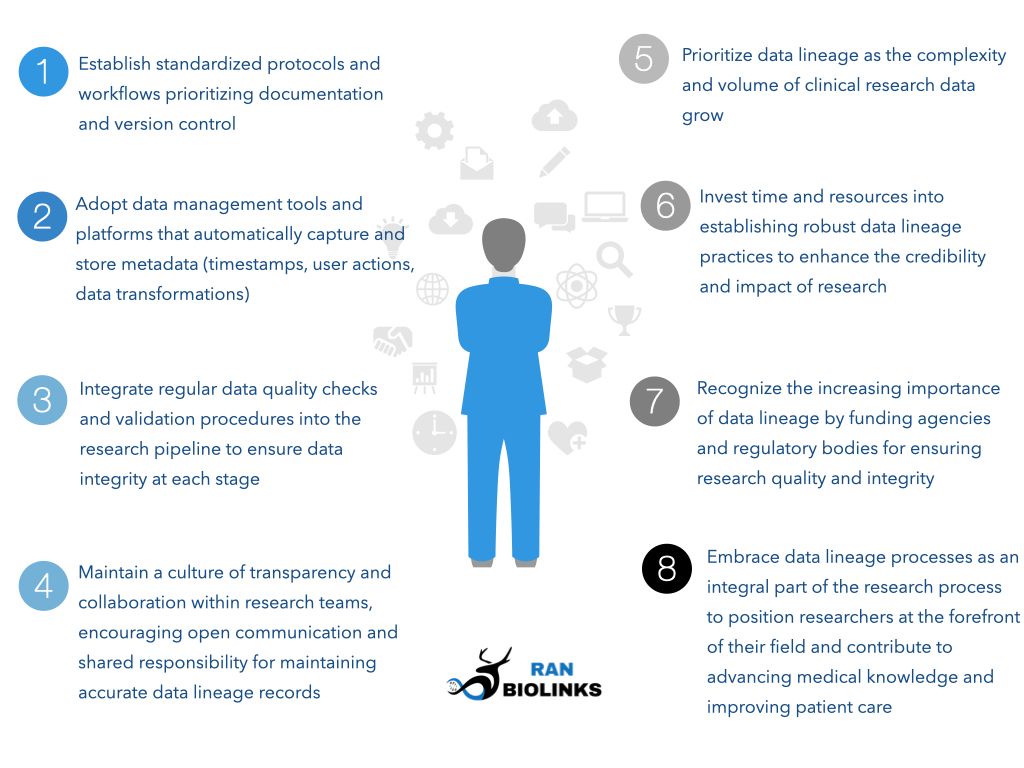
Key takeaways for implementing effective data lineage practices
REFERENCES:
 Lucy Chin
Lucy Chin
.png) Louise Niepceron
Louise Niepceron
 IBM Data and AI Team
IBM Data and AI Team
https://www.sciencedirect.com/topics/computer-science/data-lineage
 Swaminathan Nagarajan
Swaminathan Nagarajan
.png)


